[Dossier - Partie 1] Recensement Permanent
Une matière brute à révéler
Auteur : Luc Coiffier
Temps de lecture : 7 min

Depuis 2004, l’INSEE a mis en place le Recensement Permanent de la Population (RPP). Ce nouvel outil est censé apporter fraicheur et précision aux données de référence utilisées par tous les acteurs.
Qu’en est-il réellement ? Quelles en sont les limites ? Et est-ce à la portée de tous ?

LA BONNE NOUVELLE : DES DONNÉES FRAÎCHES
Il ne s’agit pas ici de décrire le processus mis en place par l’INSEE et le catalogue des données proposées. À ce sujet je vous invite à consulter l’article suivant sur le site de l’INSEE.
En introduction et uniquement pour ceux qui n’ont connu que le recensement permanent, les deux recensements précédents sa mise en place ont eu lieu en 1999 et 1990. Autrement dit les décisions étaient prises avec des données datant au mieux, de plusieurs années et au pire d’une décennie.
Depuis 2008, les données de l’année sont publiées avec régularité, et depuis 2012 le référentiel Iris est également mis à jour annuellement.

RÉGULARITÉ, STATISTIQUES ET PUIS DÉCIMALES… FORCÈMENT
Cette régularité est la source de nombreuses complexités pour celui qui n’est pas familier avec les données fournies par l’INSEE.
En effet, une donnée « libre » ne signifie pas forcément une donnée directement exploitable sans effort.
Concrètement, vous pouvez télécharger assez simplement l’ensemble des fichiers et référentiels géographiques dans différents formats, directement sur le site de l’INSEE.
Au bout de quelques minutes, vous disposez de quelques feuilles Excel, de fichiers plats, le tout contenant des milliers d’indicateurs pour différents niveaux géographiques : de l’Iris au National.
Jusque-là tout va bien.
Tant que vous êtes sur le site de l’INSEE, vous pouvez récupérer les contours administratifs des niveaux géographiques. Faites attention toutefois, ils ne correspondent pas forcément au millésime de vos données, car il y a un décalage de plusieurs semaines à plusieurs mois entre les mises en ligne des données géographiques et des données attributaires.
Puis vous ouvrez les feuilles Excel et une des premières choses que vous constatez est que les données ne sont pas entières et pas calées les unes par rapport aux autres.
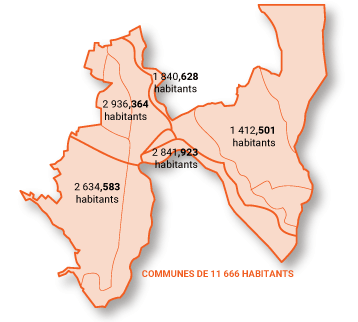
Ainsi, en 2016, la commune de Bellegarde-sur-Valserine a bien 11 666 habitants, mais la répartition sur les cinq Iris de la commune est la suivante : 1 412,501 habitants – 2 936,364 habitants – 2 634,583 habitants – 2 841,923 habitants – 1 840,628 habitants.
Et encore j’ai arrondi à la troisième décimale, il y en 11 dans le fichier Excel.
De même, selon le même recensement 2016, la commune d’Ambérieu-en-Bugey a une population totale de 14 081 habitants, dont 6813,6 hommes et 7267,4 femmes.
Ce n’est pas anormal, il s’agit juste d’une conséquence de la façon dont est mené le recensement permanent.
Par contre cela reste compliqué d’expliquer à un client que sa zone de chalandise avait 14,2 habitants en 2016, mais que cela va certainement mieux maintenant…
LE MILIEU, POURQUOI UNIQUEMENT LE MILIEU ?
Sans entrer dans le détail, le recensement permanent est basé sur un recensement tournant de 20% de la population par an sur une durée de 5 ans.
Ainsi, en 2020, l’INSEE va mettre à disposition des données issues de collectes réalisées entre 2014 et 2018, et l’année médiane (2016) sera utilisée comme référence.
Parallèlement l’INSEE met également à disposition des données moins fines sur les années postérieures à l’année médiane, au niveau départemental (2018), régional (2018) et national (2019).
Donc techniquement rien ne nous empêche d’utiliser ces données pour calculer une projection fiable des données sur 2019.
C’est pour cette raison que nous fournissons en standard, en plus des données sur l’année médiane, les mêmes indicateurs sur l’année médiane, plus 3 ans.
ARRONDIR, OUI, MAIS PAS TROP
Pour régler ce petit problème, la première idée qui vient à l’esprit est : pourquoi se compliquer la vie, il suffit d’arrondir les valeurs.
Excellente idée, faisons cela sur notre commune d’Ambérieu-en-Bugey et regardons ce que cela donne pour les 4 Iris concernés :
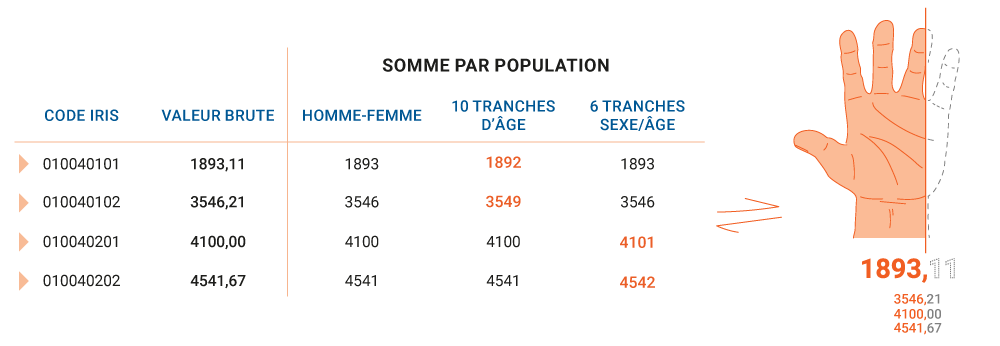
Et ce ne sont que quelques exemples de croisements simples. Je vous laisse imaginer les résultats pour les croisements CSP-Sexe-Age sur une commune avec plusieurs dizaines d’Iris. Parce que, oui, plus la donnée est « précise », plus les écarts augmentent entre les différentes évaluations.
Déjà que ce n’était pas simple d’expliquer la présence de décimales à un client, il va falloir en plus lui expliquer que la population des Iris varie en fonction des… parce que…
Bref, cette donnée a besoin d’un peu de travail pour être réellement exploitable et c’est justement ce que nous faisons depuis 2006.
Ainsi nous garantissons, non seulement des valeurs entières, mais également que les sommes des croisements retombent toujours correctement sur les sommes par Iris. Ces processus sont complètement automatisés ce qui nous permet de générer un nouveau référentiel cohérent chaque année en maintenant le niveau de qualité.
D’autant plus que nous maintenons l’ensemble des référentiels Iris depuis 1999, ce qui représente 12 référentiels Iris différents et que nous devons donc répéter cette opération 12 fois cette année, 13 fois l’année prochaine et ainsi de suite.
MÊME IRIS, PLUSIEURS CODES… POURQUOI ?
À ce stade, il me parait utile de rappeler que l’INSEE fournit bien ses données sur un référentiel Iris et un seul, et que ce référentiel change chaque année.
En passant, cela signifie que si vous n’aviez pas prévu de changer de référentiel Iris au même rythme, les nouvelles données téléchargées directement sur le site de l’INSEE ne vous sont d’aucune utilité.
Vous pourriez croire que les changements d’une année sur l’autre sont minimes et tenter de les ignorer. Disons que vous pouvez aussi tenter la chance et qu’elle pourrait être susceptible de vous sourire. Sauf que non. Désolé.
Pour illustrer mon propos, prenons un exemple : il y a deux ans, Annecy a absorbé plusieurs communes environnantes et a ainsi provoqué la modification de code de plusieurs dizaines d’Iris. Autant d’Iris qui existaient dans un référentiel et qui n’existent plus maintenant.
Et autant dire qu’avec le processus enclenché il y a quelques années de fusion des communes, ce phénomène n’est pas isolé, ni près de s’arrêter.
C’est pour cette raison qu’Asterop maintient tous les référentiels Iris depuis 1999.
Les données les plus récentes du dernier recensement sont ainsi disponibles avec le même niveau d’exigence que si vous utilisiez le référentiel 2018, ou le référentiel 2008.
Et ainsi, vous pouvez mettre à jour vos référentiels à votre rythme sans perdre le bénéfice de disposer des données les plus récentes.
250 000 C’EST BIEN, 2 MILLIONS C’EST MIEUX
En dehors des bénéfices évidents de disposer de données à jour, l’INSEE a été dans l’obligation de faire une concession qui n’est pas sans conséquence. En effet, les données du recensement de 1999 étaient non seulement disponibles à l’Iris (environ 50 000 Iris en France), mais quelques indicateurs étaient également à un niveau beaucoup plus fin : l’ilot.
Ce dernier niveau regroupait près de 250 000 unités géographiques équivalent du pâté de maisons.
D’aucuns ont imaginé pouvoir maintenir le référentiel ilot en se passant de l’INSEE, mais force a été de constater que les résultats ont été particulièrement mitigés.
Par contre, l’INSEE a mis à disposition un découpage original du Territoire en carreaux de 200 mètres de côté.

Si vous le souhaitez, vous pouvez donc télécharger un peu plus de 14 millions de carreaux, dont une écrasante majorité est vide de population.
Même s’il est possible de les livrer tels quels, il faut admettre que c’est plutôt indigeste à intégrer et que l’absence de cohérence avec les niveaux supérieurs (Iris, commune, …) ne participe pas à une utilisation simplifiée.
Donc, plutôt de que les livrer en l’état, nous avons décidé de créer un niveau ultra-fin en croisant les carreaux et les Iris.
Et c’est ainsi que plus de 2 millions de K#Iris sont disponibles, maintenus, compatibles avec les Iris de tous les millésimes.
Au passage nous avons également intégré les carreaux sans population, mais avec des emplois grâce à un autre croisement avec la base SIRENE. Mais c’est une autre histoire.
PLUS C’EST FORCÉMENT MIEUX, DONC 24 MILLIONS
S’il fallait désigner une star dans les données proposées par l’INSEE, il s’agirait du fichier détail contenant des informations sur plus de 24 millions de résidences principales.
Ce fichier est une véritable mine d’or : vous y trouverez non seulement des informations sur les logements (taille, nombre de pièces…) mais également sur la composition des ménages qui les occupent.

Vous ne trouvez pas le croisement que vous souhaitez dans les indicateurs disponibles au niveau Iris ?
Pas de problème, il y a de bonnes chances que l’exploitation du fichier détail vous permette de créer cet indicateur.
Pour donner un exemple, les indicateurs de cycle de vie que nous avons créés sont entièrement basés sur une exploitation fine du fichier détail.
Mais ce n’est qu’un exemple et il y a des dizaines d’utilisations potentielles.
LA SIMPLICITÉ EST PARFOIS COMPLEXE
Notre première réaction lorsque l’INSEE a mis en place le recensement permanent a été : « Enfin ! »
Et nous nous sommes littéralement précipités pour tout récupérer au cas où l’INSEE changerait d’avis.
Nous avons confirmé immédiatement que la donnée était bien libre d’accès, c’est-à-dire gratuite à télécharger et à utiliser sans limitation d’usage.
Si nous avons un jour l’occasion de partager un café, vous entendrez probablement que la donnée doit être respectée, faute de quoi elle a une forte tendance à se venger. Et ceci est d’autant plus vrai que la donnée est riche et complexe.
Or, nous sommes ici dans un cas de complexité aigüe, doublé d’un syndrome de mise à jour permanent. Bref, tous les ingrédients sont réunis pour faire exploser les coûts de mise en forme et de maintenance.
Donc oui la donnée est « gratuite », mais plutôt au sens libre d’accès que ne coûtant rien.
Pour l’avoir mis en œuvre, je vous confirme que, d’une part, l’effort nécessaire pour intégrer correctement et rendre exploitables ces données est extrêmement important et que, d’autre part, les processus à mettre en œuvre pour en garantir la cohérence et la qualité sont complexes.
L’excellente nouvelle est que nous avons également confirmé la richesse de l’ensemble. Ici, nous ne parlons pas de quelques centaines d’indicateurs, mais bien de dizaines de millions de croisements possibles, dont nous n’avons qu’à peine effleuré le potentiel dans cet article.
À ce sujet, nous reviendrons sur l’exploitation avancée des données mises à disposition dans un prochain dossier.
À propos de notre auteur Luc Coiffier, Directeur Général d’Asterop.
Luc Coiffier est co-fondateur et Directeur Général Délégué d’Asterop. Il est particulièrement en charge des aspects technologique, data et méthodologique. Issu d’une formation mathématique & informatique, il a également été Directeur R&D et créateur d’un SIG français majeur.
Leader de l’optimisation des réseaux de points de vente, Asterop crée des solutions personnalisées et propose des données de qualité pour fiabiliser vos décisions d’implantations et de ciblage.
Intéressé ? Nos équipes commerciales répondent à vos questions